Linux Zoned Storage Support Overview
Zoned block device support was added to the Linux® kernel in version 4.10. Subsequent versions improved this support and added new features beyond the raw block device access interface. More advanced features such as device mapper support and ZBD-aware file systems are now available.
Overview
Application developers can use zoned block devices by means of various I/O paths, can control them with different programming interfaces, and can expose zoned block devices in different ways. A simplistic representation of the various access paths is shown in the figure below.
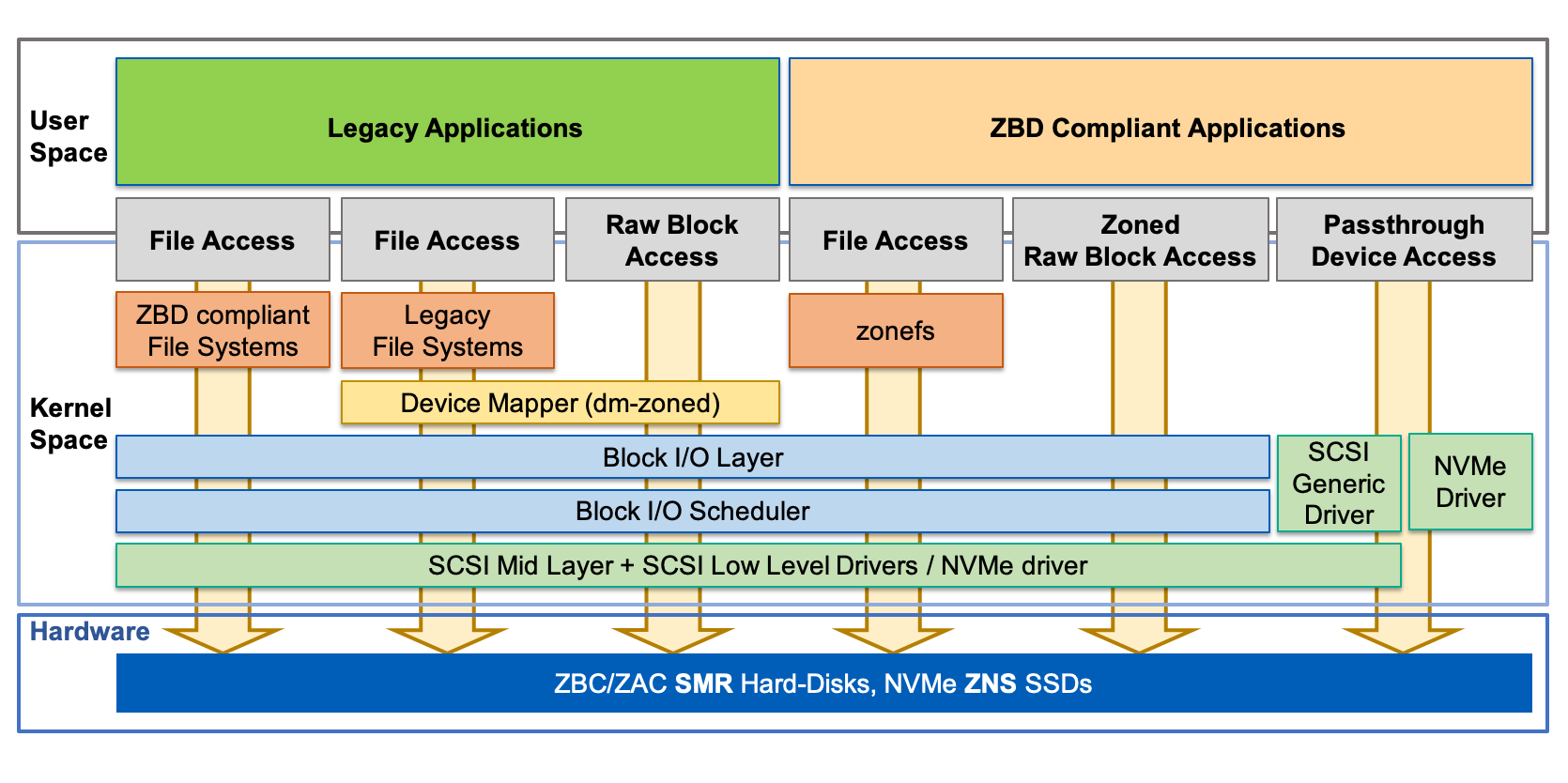
Three different I/O paths implement two POSIX compatible interfaces that hide the write constraints of the sequential zones of the zoned block devices. These three I/O paths can run legacy applications (applications that have not been modified to implement fully-sequential write streams).
-
File Access Interface This is the interface that file systems implement to allow applications to organize their data into files and directories. Two different implementations of the file access interface are available:
-
ZBD Compliant File System: With this implementation, the file system is modified to directly handle the sequential write constraint of zoned block devices. Random writes to files by applications are transformed into sequential write streams by the file system, concealing the device constraints from the application. An example of this is the F2FS file system.
-
Legacy File System: With this implementation, an unmodified file system is used and the device-sequential write constraint is handled by a device mapper target driver that exposes the zoned block device as a regular block device. This device mapper is called dm-zoned. Its characteristics are discussed in detail here.
-
-
Raw Block Access Interface This is the raw block device file access interface that can be used by applications to directly access data stored on the device. Similar to the legacy file system case, this interface is implemented using the dm-zoned device mapper target driver to hide the sequential write constraints from the application.
Three additional interfaces are available to applications that have been written or modified to comply with the sequential write constraint of zoned block devices. These interfaces directly expose the device constraints to applications which must ensure that data is written using sequential streams that start from the write-pointer positions of the zones.
-
File Access Interface: This special interface is implemented by the zonefs file system. zonefs is a very simple file system that exposes each zone of a zoned block device as a file. But unlike regular POSIX file systems, the sequential write constraint of the device is not automatically handled by zonefs. It is the responsibility of the application to sequentially write files that represent zones.
-
Zoned Raw Block Access Interface: This is the counterpart of the Raw Block Access Interface (without any intermediate driver to handle the device constraints). An application can use this interface by directly opening the device file that represents the zoned block device to gain access to zone information and management operations that are provided by the block layer. Linux System Utilities, for example, use this interface. Physical zoned block devices, as well as logically-created zoned block devices (e.g. zoned block devices created with the dm-linear device mapper target), support this interface. The libzbd user library and tools can simplify the implementation of applications that use this interface.
-
Passthrough Device Access Interface This is the interface (provided by the SCSI generic driver (SG) and the NVMe driver) that allows an application to send SCSI or NVMe commands directly to a device. The kernel interferes minimally with the commands sent by applications, resulting in the need for an application that can handle all device constraints itself (e.g. Logical and physical sector size, zone boundaries, command timeout, command retry count, etc). User-level libraries such as libzbc and libnvme can greatly simplify the implementation of applications that use this interface.
Kernel Versions
The initial release of the zoned block device support with kernel 4.10 was limited to the block layer ZBD user interface, SCSI layer sequential write ordering control and native support for the F2FS file system. Following kernel versions added more features such as device mapper drivers and support for the block multi-queue infrastructure.
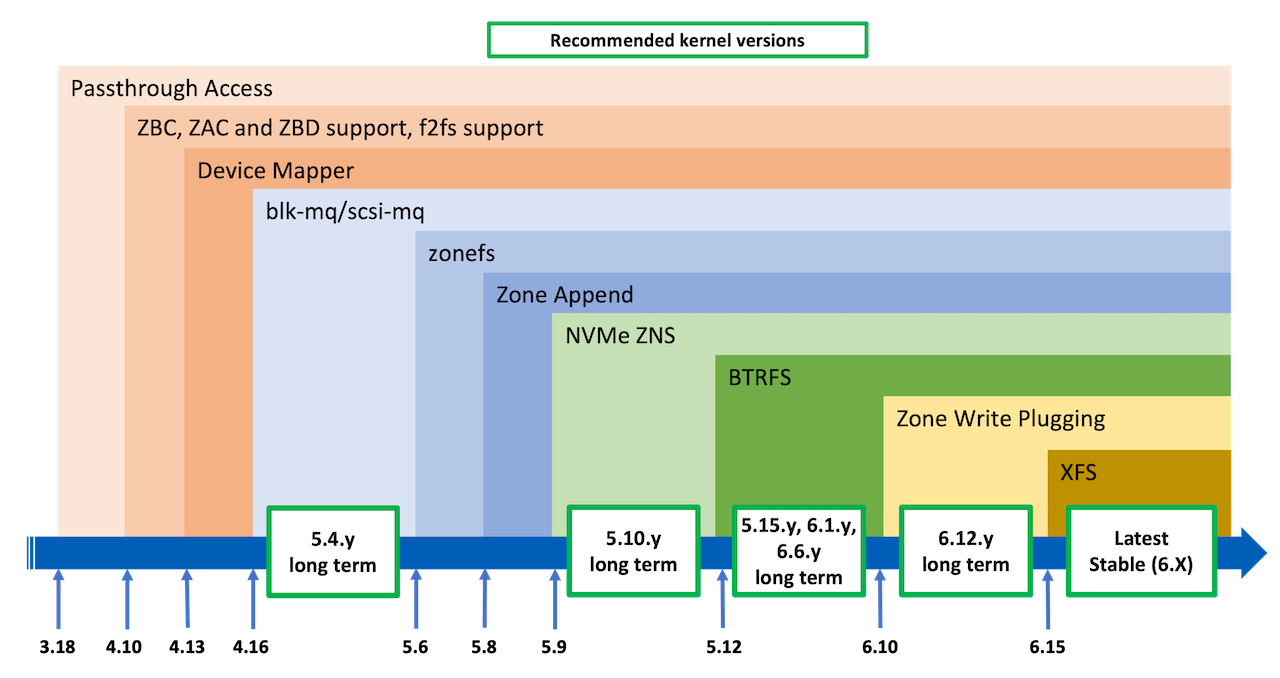
The figure below summarizes the evolution of zoned block device support with kernel versions.
-
Passthrough Access Support (SG Access) Support for exposing host managed ZBC/ZAC hard-disks as SCSI generic (SG) nodes was officially added to kernel 3.18 with the definition of the device type
TYPE_SCSIfor SCSI devices and with the definition of the device classATA_DEV_ZACfor ATA devices. For kernels older than version 3.18, SATA host managed ZAC disks will not be exposed to the users as SG nodes nor as block device files. These older kernels will simply ignore SATA devices reporting a host managed ZAC device signature and the devices will not be usable in any way. For SCSI disks or SATA disks connected to a compatible SAS HBA, host managed disk will be accessible by the user through the node file created by the SG driver to represent these disks. -
Zoned Block Device Access and F2FS Support The block I/O layer zoned block device support added to kernel version 4.10 enables exposing host managed ZBC and ZAC disks as block device files, similarly to regular disks. This support also includes changes to the kernel libata command translation to enable SCSI ZBC zone block commands translation to ZAC zone ATA commands. For applications relying on SCSI generic direct access, this enables handling both ZBC (SCSI) and ZAC (ATA) disks with the same code (e.g. ATA commands do not need to be issued). Access to zoned block devices is also possible using the disk block device file (e.g. /dev/sdX device file) with regular POSIX system calls. However, compared to regular disks, some restrictions still apply (see Kernel ZBD Support Restrictions).
-
Device Mapper and dm-zoned Support With kernel version 4.13.0, support for zoned block devices was added to the device mapper infrastructure. This support allows using the dm-linear and dm-flakey device mapper targets on top of zoned block devices. Additionally, the dm-zoned device mapper target driver was also added.
-
Block multi-queue and SCSI multi-queue Support With kernel version 4.16.0, support for the block multi-queue infrastructure was added. This improvement enables using host managed ZBC and ZAC disks with the SCSI multiqueue (scsi-mq) support enabled while retaining support for the legacy single queue block I/O path. The block multi queue and scsi-mq I/O path are the default since kernel version 5.0 with the removal of the legacy single queue block I/O path support.
-
zonefs Kernel 5.6.0 first introduced the zonefs file system which exposes zones of a zoned block device as regular files. zonefs being implemented using the kernel internal zoned block device interface, all types of zoned block devices are supported (SCSI ZBC, ATA ZAC and NVMe ZNS).
-
Zone Append Operation Support Kernel version 5.8.0 introduced a generic block layer interface for supporting zone append write operations. This release also modifies the SCSI layer to emulate these operations using regular write commands. With the introduction of NVMe ZNS support (see below), this emulation unifies the interface and capabilities of all zoned block devices, simplifying the implementation of other features such as file systems.
-
NVM Express Zoned Namespaces With kernel version 5.9, support for the NVMe ZNS command set was added. This enables the nvme driver with the command set enhancements required to discover zoned namespaces, and registers these with the block layer as host managed zone block devices. This kernel release only supports devices that do not implement any of the zone optional characteristics (ZOC), and also requires that the device implements the optional Zone Append command.
-
BTRFS Support Support for the BTRFS file system was added in kernel version 5.12. This POSIX compliant general purpose file system completely hides the sequential write constraint of zoned block devices to users, and thus allows the execution of unmodified applications using files to manage data.
-
Zone Write Plugging Kernel version 6.10 introduced an improved write ordering control for zoned block devices. This is implemented as a generic feature of the block layer. Zone Write Plugging replaces the older write ordering Zone Write Locking mechanism implemented within the mq-deadline block I/O scheduler.
-
XFS Support With kernel 6.15, the XFS file system gained native zoned block device support.
Recommended Kernel Versions
All kernel versions since 4.10 include zoned block device support. However, as shown in the figure Kernel versions and features, some versions are recommended over others.
-
Long Term Stable (LTS) Versions Kernel versions 5.4, 5.10, 5.15 6.1, 6.6, and 6.12 are long term stable kernel versions that include bug fixes backported from fixes in the mainline (development) kernel. These versions benefit from stability improvements that were developed for higher versions. Fixes to the zoned-block-device support infrastructure are also backported to these versions.
-
Latest Stable Version While not necessarily marked as a long-term stable version, the latest stable kernel version receives all bug fixes developed in the main line of kernel development. Except if the version is tagged as a long term support version, back-port of fixes to a stable kernel version stops with the switch of the following version from mainline to stable. Using a particular kernel stable version for a long time is thus not recommended.
For any stable or long term stable kernel version, we recommend that system administrators use the latest available release within that version to ensure that all known fixes are applied.
The list of current mainline, stable and long term stable kernel versions can be found on The Linux Kernel Archives site.
ZBD Support Restrictions
In order to keep changes to the block layer code to a minimum, various existing features of the block layer were reused (for instance, automatic splitting of IOs on LBA boundaries implemented for software RAID is one example of this reuse). Kernel components that are not compatible with the behavior of zoned block devices or were too complex to change were left unmodified. This resulted in a set of constraints that constrain all zoned block devices that work with Linux.
-
Zone size ZBC, ZAC, and ZNS standards do not impose any constraints on the zone layout of a device (this means that zones can be of any size), but kernel ZBD support is restricted to zoned devices on which all zones are of equal size. The zone size must also be equal to a number of logical blocks that is a power of 2. Only the last zone of a device may have a smaller size (a so called runt zone). This zone-size restriction allows the kernel code to use the block layer "chunked" space management that is normally used for software RAID devices. The chunked space management uses power-of-two arithmetic (bit shift operations) to determine which chunk (i.e. which zone) is being accessed and it also ensures that block I/O operations do not cross zone boundaries.
-
Unrestricted Reads The ZBC and ZAC standards define the URSWRZ bit, which determines whether a device will return an error when a read operation is directed at unwritten sectors of a sequential write required zone. (An example of this kind of read operation is when a read command accesses sectors that are after the write-pointer position of a zone.) Linux supports only ZBC and ZAC host-managed hard disks that allow unrestricted read commands. In other words, Linux supports only SMR hard disks that report that the URSWRZ bit is not set. This restriction has been added to ensure that the block-layer disk-partition-scanning process does not result in read commands that fail whenever the disk partition table is checked.
-
Direct IO Writes The kernel page cache does not guarantee that cached dirty pages will be flushed to a block device in sequential sector order. This can lead to unaligned write errors if an application uses buffered writes to write to the sequential write required zones of a device. To avoid this pitfall, applications that directly use a zoned block device without a file system should always use direct I/O operations to write to the sequential write required zones of a host-managed disk (that is, they should issue
write()system calls with a block device "file open" that uses theO_DIRECTflag). -
Zone Append The ZNS specifications define the optional "Zone Append" command. This command can be used instead of regular write commands when the host must write data, but requires the device to report where the data was placed. This allows an efficient host implementation, because (1) the write pointer does not have to be tracked and (2) write commands do not have to be ordered. The Linux IO stack has been enabled to use this with kernel version 5.8 and the NVMe driver requires the device to support this optional command in order for the namespace to be usable through the kernel.
All known ZBC and ZAC host-managed hard disks that are available on the market today have characteristics compatible with these requirements and can operate with a ZBD-compatible Linux kernel.